
Best Machine Learning Algorithms for Finance
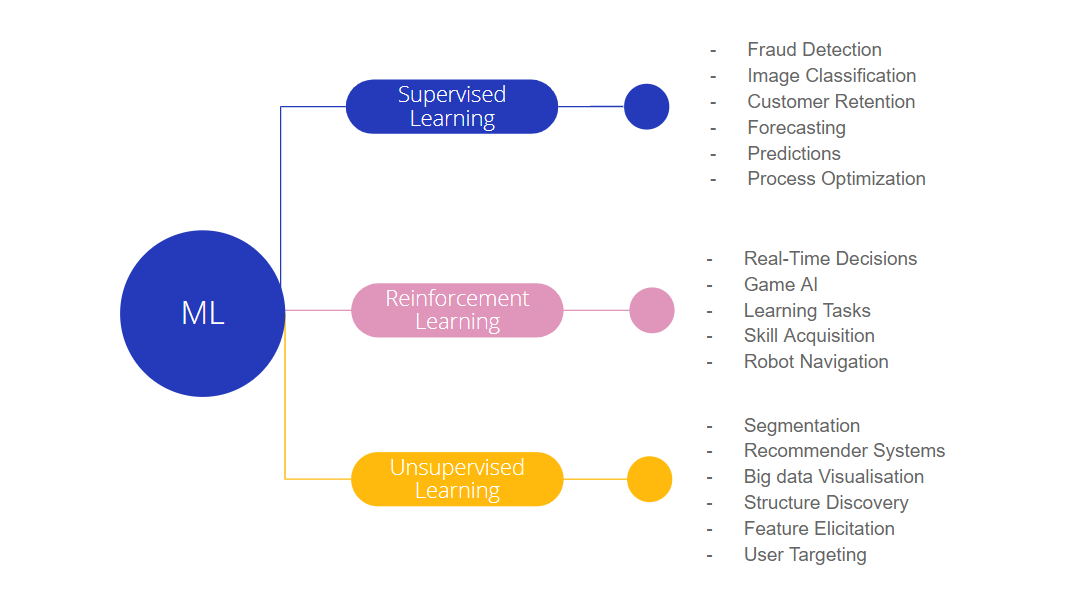
Machine learning is a rapidly growing field with applications in a wide variety of industries, including finance. In finance, machine learning algorithms can be used to solve a variety of problems, such as:
- Predicting stock prices: Machine learning algorithms can be used to predict the future prices of stocks, based on historical data. This information can be used by investors to make more informed decisions about when to buy and sell stocks.
- Fraud detection: Machine learning algorithms can be used to identify fraudulent transactions, which can help financial institutions protect themselves from financial loss.
- Risk management: Machine learning algorithms can be used to assess the risk of different investments, which can help investors make more informed decisions about where to allocate their capital.
- Customer segmentation: Machine learning algorithms can be used to segment customers into different groups, based on their characteristics and behavior. This information can be used by financial institutions to target their marketing efforts more effectively.
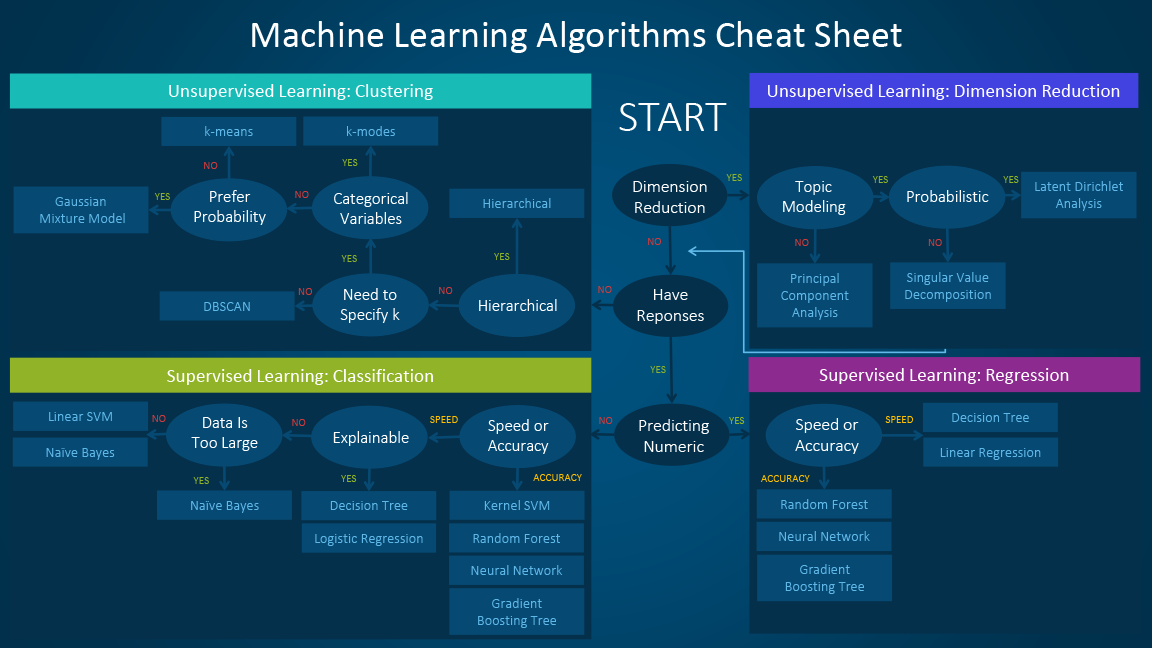
There are a wide variety of machine learning algorithms that can be used for finance, each with its own strengths and weaknesses. The best algorithm for a particular task will depend on the specific data and the desired outcome.
In this article, we will discuss some of the best machine learning algorithms for finance, and provide examples of how they can be used to solve real-world problems.
Linear Regression
Linear regression is one of the simplest and most popular machine learning algorithms. It can be used to predict a continuous value, such as the price of a stock, based on a linear relationship between the input features and the output value.
The linear regression model is defined by the following equation:
y = b0 + b1x1 + b2x2 + ... + bnxn
where:
- y is the predicted value
- b0 is the intercept
- b1, b2, ..., bn are the slope coefficients
- x1, x2, ..., xn are the input features
To train a linear regression model, we need to find the values of the slope coefficients that minimize the error between the predicted values and the actual values. This can be done using a variety of optimization techniques, such as gradient descent.
Linear regression is a very powerful algorithm that can be used to solve a variety of problems in finance. For example, it can be used to:
- Predict stock prices
- Forecast economic growth
- Analyze the relationship between different financial variables
Logistic Regression

Logistic regression is a type of supervised learning algorithm that can be used to predict the probability of an event occurring. It is a more powerful alternative to linear regression for problems where the output value is categorical, such as predicting whether a loan will be repaid.
The logistic regression model is defined by the following equation:
p(y = 1 | x) = 1 / (1 + exp(-(b0 + b1x1 + b2x2 + ... + bnxn)))

where:
- p(y = 1 | x) is the probability of the event occurring
- b0 is the intercept
- b1, b2, ..., bn are the slope coefficients
- x1, x2, ..., xn are the input features
To train a logistic regression model, we need to find the values of the slope coefficients that maximize the likelihood of the model's predictions. This can be done using a variety of optimization techniques, such as gradient descent.
Logistic regression is a very powerful algorithm that can be used to solve a variety of problems in finance. For example, it can be used to:
- Predict whether a loan will be repaid
- Identify fraudulent transactions
- Segment customers into different groups
Decision Trees
Decision trees are a type of supervised learning algorithm that can be used to solve both classification and regression problems. They work by building a tree-like structure of decisions, where each decision node represents a test on an input feature, and each leaf node represents a predicted output value.
Decision trees are very easy to understand and interpret, which makes them a popular choice for financial applications. However, they can also be prone to overfitting, which means that they can learn the training data too well and make inaccurate predictions on new data.
The decision tree algorithm is defined by the following steps:

- Start with a root node that represents the entire training data set.
- For each input feature, create a decision node that tests for the presence of that feature.
- For each decision node, create a child node for each possible value of the feature.
- Repeat steps
Post a Comment